تاثیر کلان داده در بازاریابی مبتنی بر ایمیل چیست ؟
امروزه، عصر تکنولوژی به عصر ارتباطات و استفاده از ابزار ها بدل گشته است. تکنولوژی های گوناگون تقریبا به طور مساوی در بین جوامع گسترده شده اند. حال آنکه رشد و توسعه ی فرهنگ یک جامعه را با ابزارشناسی و ابزار سازی آن میتوان سنجید. به عبارت دیگر به کار گیری دانش و تکنولوژی برای دستیابی به اهداف فردی و سازمانی در بین حوامع گوناگون و قشر های مختلف یکسان نیست.
ایمیل در میان ابزارهای مورد استفاده در جامعه امروزی، جایگاه ویژه ای دارد. ابزاری بسیار ارزان قیمت که در عین کاهش هزینه های اطلاع رسانی و تبلیغات و روابط عمومی، دانش و تخصص استفاده از آن نیز بسیار ساده و سطحی به نظر میرسد. همین نگرش ساده انگارانه باعث شده است، در حوزه ایمیل در کشورمان گرفتار یک فرهنگ "ابزارسوزی" شویم.
انبوه ایمیل هایی که روزانه از گروههای مختلف دریافت میکنیم، فهرست های چند میلیونی ایمیل که با قیمت های بسیار ناچیز ،دست به دست میگردند، سرمایه گذاری های قابل توجه در حوزه ایمیل مارکتینگ بدون بازگشت قابل توجه و در نهایت، بی تفاوت شدن جامعه هدف نسبت به این ابزار قدرتمند و کارآمد، همگی میتواند نشان دهنده نیاز به تغییر نگرش در این حوزه باشد.
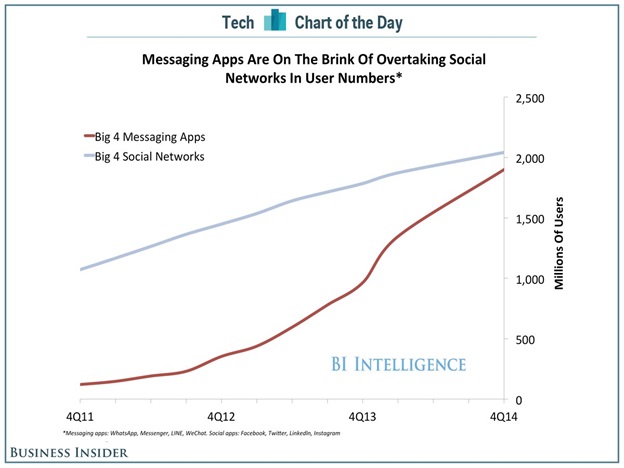
فورستر پیشبینی می کند که در سال 2015 بازاریابان، بیش از 258 میلیارد ایمیل- با جهش 63% نسبت به سال 2014- خواهند فرستاد[5]

این ابزار سوزی از آنجا ناشی می شد که جز موارد معدودی مانند زمان ارسال، عنوان، عنوان فرستنده و چند پارامتر کوچک دیگر متغیر دیگری در دسترس نبود. همچنین در سال های اخیر دیگر مدل های پوشاننده سلیقه همه به عنوان پیام های هرزنامه تلقی شده و مصرف نمیشوند و بازاریابان باید تاکتیک های خود را در صندوق ورودی ایمیل مصرف کننده ها تغییر دهند.[2]
کلان داده تقریبا به تمامی ابعاد کسب و کارها را در سالهای اخیر نزدیک شده است. این امر به برند ها این امکان را می دهد که کاملا شخصی سازی شده و موثر کمپین هایی برای تحلیل جزئیات داده های مشتریان راه اندازی کنند. بازاریابان ایمیلی معمولا از کلان داده برای هدف قرار دادن مخاطبان با توجه به خرید قبلی و تاریخچه جست و جوی اینترنتی آنان استفاده می کنند. وارنوک[1] می گوید: " بازاریابان ایمیلی به صورت فزاینده ای متوجه ارزش کمپین های تنظیم کننده و جهت دهنده رفتار و فرستادن پیام شخصی سازی شده بر اساس رفتار مصرف کننده شده اند" [2]
تا کنون تنها 25 % کسب و کارها داده های شخصی خود را برای فعالیت های زمان محدود خود استفاده می کردند[1] . به همین خاطر می توان گفت اکثر بازاریابان هنوز از این فرصت کشف از دست رفته آگاه نیستند..
بازاریابان اغلب در گزارشات فصلی نرخ های عوامل کلیدی مهم را تنها می خوانند. اما این گزارشات به ما در بازاریابی ایمیلی نمی گوید کدام مقاله بیشترین خواننده را داشته است و یا اینکه چه نوع اشخاصی درخواست تماس تلفنی شما را قبول کرده اند؟!
داده های مشتریان بر اساس اهمیت به 4 دسته اصلی از دید بازاریابان تقسیم می شوند:[5]
1. تعاملات ایمیلی: تعاملات ایمیلی ساده داده هایی مانند اینکه کجا کاربر کلیک نموده و نرخ باز شدن، لینک های باز شده، کلیک ها، نرخ تبدیل مشتری، و معیارهای مرتبط را مشخص می سازد.
2. تعاملات وبسایت : دسترسی به اطلاعات دریافت کننده ها به بازاریابان امکان درک بهتر و عمیق نحوه جست و جوی وبسایت را می دهد.
3. داده های خرید : داده خرید قبلی داده بسیار ارزشمندی برای پیش بینی حرکت بعدی مشتری است. با نگاه کردن به خرید قبلی مشتری می توان ایمیل را کاملا شخصی کرد.
4. ارجحیت های پروفایل مشتری: داده های پروفایل مشتری، مانند محل سکونت، سن، جنسیت هم در درجه اهمیت بعدی قرار دارند.
با تحلیل داده ها، بازاریابان می توانند محتوایی که برای مخاطب ارزشمند بوده را متوجه شوند. اگر خواننده ها روی محصول با توجه به این محتوی کلیک کنند به این معنی است که محتوی مورد پسند و ارزشمند بوده است و اگر این امر صورت نپذیرد متوجه می شوند که باید تغییرات در چه زمینه هایی صورت پذیرد [1] .
کلان داده علاوه بر اینکه به ما نوع پیام هایی که باز می شوند را می گوید، بلکه زمان و مکان باز شدن ایمیل را با تفکیک های مختلف معین می سازد[2] .
در شرکت آرمیتیس که شرکت نرم افزاری ایرانی است نیز این تکنیک های کلان داده ای به کار گرفته می شوند. نمونه ای از خروجی این کلان داده به صورت زیر است:
23.63 درصد ایمیل های ارسال در ساعت اول، 9.52 درصد در ساعت دوم، 6.33 درصد در ساعت سوم و 4.8 درصد در ساعت چهارم پس از ارسال باز می شوند، این رقم برای روز بعد از ارسال به 0.63 درصد کاهش پیدا می کند. بهترین زمان ارسال برای باز شدن ایمیل ها ساعت 8 تا 9صبح و یا 3 تا 4 بعد از ظهر است. بهترین زمان برای کلیک روی ایمیل های باز شده ساعت 8 تا 9 صبح و یا 3تا 8 بعد از ظهر است. 5.9 درصد ایمیل ها بین 12 تا 6 صبح، 38.7 درصد بین 6 تا 12 ظهر، 25.8 درصد بین 12 تا 6 بعد از ظهر و 29.6 درصد بین 6 تا 12 شب ارسال می شوند. [6]
باید زمانی که شخص تمایل بیشتری به باز کردن ایمیل را دارد متوجه شد. برای این کار باید باز کردن های قبلی وی را دنبال کرد. این امر و تفکیک جغرافیایی و بخش بندی، موجی از تمایز و شخصی سازی شدن را به ارمغان می آورد.[2]
با کلان داده به راحتی می توان فهمید کدام بخش بازار هدف شما مصرف کننده چه نوع محتوایی هستند. با دانستن اینکه چه کسی، چه چیزی را می خواند، محتوی می تواند بسیار مرتبط با گیرنده باشد
منابع
1.
How big data can enhance B2B email marketing
http://www.imediaconnection.com/content/37539.asp#Ksz2dpUOYjGTFol3.99
2. Better Data and Personalization Are the Future of Email marketing http://www.businessnewsdaily.com/7315-future-of-email-marketing.html
3. Big data means big opportunities in email marketing
http://www.responsys.com/blogs/nsm/email-marketing/big-data-means-big-opportunities-in-email-marketing/
4. https://www.forrester.com/Forrester+Research+Email+Marketing+Forecast+2012+To+2017+US/fulltext/-/E-RES85321
5. http://www.responsys.com/blogs/nsm/email-marketing/big-data-means-big-opportunities-in-email-marketing/
6. کتاب 21 نکته در ایمیل مارکتینگ- نوشته شرکت آرمیتیس